
This describes how I have implemented my own neural network. The article focuses mainly on the math and calculations, in order to save somewhere the know how and how I did it.
This is sub-layout for documentation pages
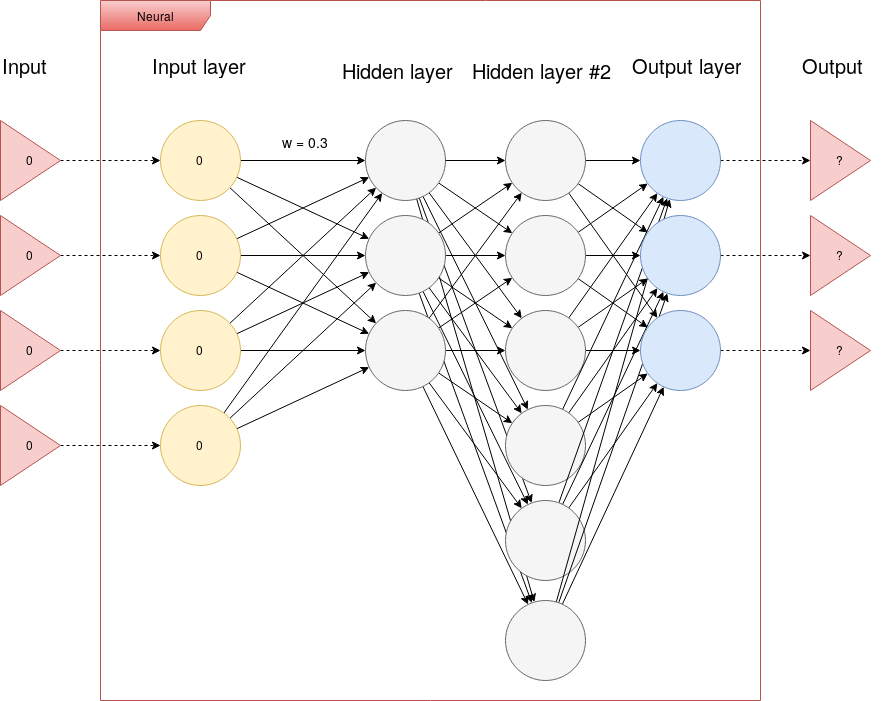
Neural network can be seen as a multivariable function. We give it multiple inputs, and we get multiple outputs.
The neural network we will be discussing here,
is neural network, which has one input layer, \(n \in <2, \inf>\) hidden
layers, and one output layer.
Here is an illustration of such a neural network:
Let's start with some axioms (or definitions), to have some
naming convention we can use.
Note: These definitions are defined by me, and do not necesarrily have to apply
to all existing implementations of neural networks that exist in the world,
but they apply to my implementation precisely!
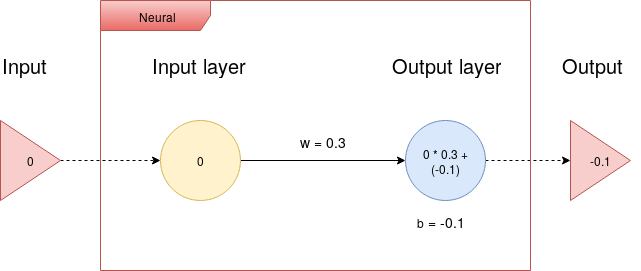
Informally, feed forward is an operation, which takes an input, and
pulls it through the neural network to generate an output.
Let's imagine one input and one output neuron, then, the output calculation
is shown by the following illustration:
So, what we need to calculate for each layer are two values,
\(\Delta w\) and \(\delta b\)
\(\Delta w\) tells, how we have to alter weights going into the currenlty processed layer,
with respect to the error.
\(\delta b\) tells, how we have to alter biases for all nodes of the currenlty processed layer,
with respect to the error.
(understanding, that we never calculate back propagation for the input layer \(L_1\))
In order to unwrap this complex math topic, let's start with some definitions:
Because, from experience, it is easier to understand someting from example,
than from bunch of definitions, here is calculated example.
Let's have following neural network:
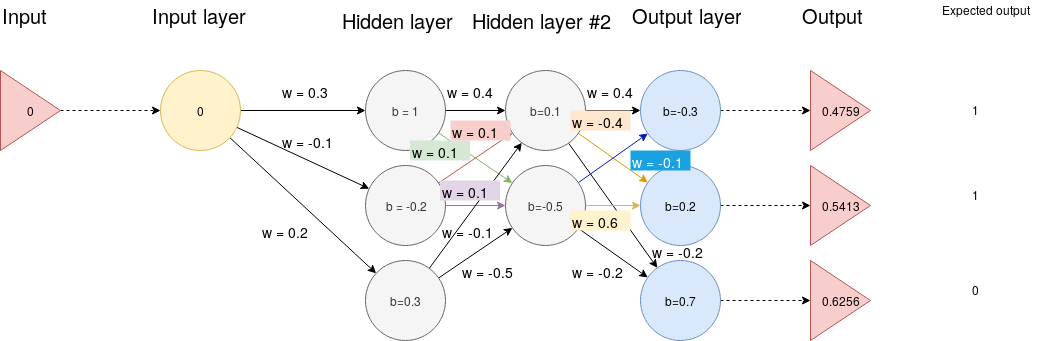
The actual network weight matrix between layers \(L_3\) and \(L_4\) is \(W_{3,4}\)
We need to calculate \(\Delta W_{3,4}\), for which applies the equation above
Error from output \(E_4\) is expected result - \(O_4\), because \(L_4\) is the last layer
\(E_4 =
\begin{bmatrix}1\\1\\0\end{bmatrix} -
\begin{bmatrix}0.4759\\0.5413\\0.6256\end{bmatrix}=
\begin{bmatrix}0.5241\\0.4587\\-0.6256\end{bmatrix}
\)
Gradient \(G(O_4)\) results in
\( G(O_4) =
\begin{bmatrix}0.1966\\0.2475\\0.2444\end{bmatrix}
\)
Therefore \(\Delta w_{3,4}\) is
\(\Delta w_{3,4} = l_r * (G(O_4) \circ E_4) * O_3^\top \)
\( =
0.1 *
( \begin{bmatrix}0.1966\\0.2475\\0.2444\end{bmatrix} \circ
\begin{bmatrix}0.5241\\0.4587\\-0.6256\end{bmatrix} ) *
\begin{bmatrix}0.5938 & 0.3386\end{bmatrix}
\)
\(=
\begin{bmatrix}0.0077 & 0.0044\\0.0067 & 0.0038\\-0.0087 & -0.0049\end{bmatrix}
\)
We will then add \(\delta w_{3,4}\) to \(W_{3,4}\)
\(\Delta b_4 = l_r * (G(O_4) \circ E_4) \)
\(= 0.1 *
( \begin{bmatrix}0.1966\\0.2475\\0.2444\end{bmatrix} \circ
\begin{bmatrix}0.5241\\0.4587\\-0.6256\end{bmatrix} )
= \begin{bmatrix}0.0130\\0.0113\\-0.0146\end{bmatrix} \)
We will then add \(\Delta b_4\) to \(B_4\)
Error from output \(E_3\) is
\(E_3 = (W_{3,4} + \Delta w_{3,4})^\top * E_4\)
\(=
(\begin{bmatrix}0.4 & -0.1\\-0.4 & 0.6 \\ -0.2 & -0.2\end{bmatrix} +
\begin{bmatrix}0.0077 & 0.0044\\0.0067 & 0.0038\\-0.0087 & -0.0049\end{bmatrix})^top *
\begin{bmatrix}0.5241\\0.4587\\-0.6256\end{bmatrix}
=
\begin{bmatrix}0.1638\\0.3551\end{bmatrix}
\)
Gradient \( G(O_3) =
\begin{bmatrix}0.2411\\0.2239\end{bmatrix}
\)
Therefore
\(\Delta w_{2,3} = l_r * (G(O_3) \circ E_3) * O_2^\top \)
\( =
0.1 *
( \begin{bmatrix}0.2411\\0.2239\end{bmatrix} \circ
\begin{bmatrix}0.1638\\0.3551\end{bmatrix} ) *
\begin{bmatrix}0.7310 & 0.4501 & 0.5744\end{bmatrix}
\)
\(=
\begin{bmatrix}0.0028 & 0.0017 & 0.0022\\0.0058 & 0.0035 & 0.0045\end{bmatrix}
\)
We will then add \(\delta w_{2,3}\) to \(W_{2,3}\)
\(\Delta b_3 = l_r * (G(O_3) \circ E_3) \)
\(= 0.1 *
( \begin{bmatrix}0.2411\\0.2239\end{bmatrix} \circ
\begin{bmatrix}0.1638\\0.3551\end{bmatrix} )
= \begin{bmatrix}0.0039\\0.0079\end{bmatrix} \)
Error from output \(E_2\) is
\(E_2 = (W_{2,3} + \Delta w_{2,3})^\top * E_3\)
\(=
(\begin{bmatrix}0.4 & 0.1 & -0.1\\0.1 & 0.1 & -0.5\end{bmatrix} +
\begin{bmatrix}0.0028 & 0.0017 & 0.0022\\0.0058 & 0.0035 & 0.0045\end{bmatrix})^top *
\begin{bmatrix}0.1638\\0.3551\end{bmatrix}
=
\begin{bmatrix}0.1036\\0.0534\\-0.1919\end{bmatrix}
\)
Gradient \( G(O_2) =
\begin{bmatrix}0.1966\\0.2475\\0.2444\end{bmatrix}
\)
Therefore
\(\Delta w_{1,2} = l_r * (G(O_2) \circ E_2) * O_1^\top \)
\( =
0.1 *
( \begin{bmatrix}0.1966\\0.2475\\0.2444\end{bmatrix} \circ
\begin{bmatrix}0.1036\\0.0534\\-0.1919\end{bmatrix} ) *
\begin{bmatrix}0\end{bmatrix}
\)
\(=
\begin{bmatrix}0\\0\\0\end{bmatrix}
\)
We will then add \(\delta w_{1,2}\) to \(W_{1,2}\)
\(\Delta b_2 = l_r * (G(O_2) \circ E_2) \)
\(= 0.1 *
( \begin{bmatrix}0.1966\\0.2475\\0.2444\end{bmatrix} \circ
\begin{bmatrix}0.1036\\0.0534\\-0.1919\end{bmatrix} )
= \begin{bmatrix}0.0020\\0.0013\\-00046\end{bmatrix} \)
Congratulations, we have successfully finished the back propagation of the neural network
The wolfram mathematica notebook with these calculations can be downloaded
here

